Code
Please visit this page for the code implementation of the LP method.
Formally, a linear program is an optimization problem of the form
minimize subject to c⊤xAx=bx≥0, where c∈Rn,b∈Rm, and A∈Rm×n. The vector inequality x≥0 means that each component of x is nonnegative. Several variations of this problem are possible; for example, instead of minimizing, we can maximize, or the constraints may be in the form of inequalities, such as Ax≥b or Ax≤b. Here A is an m×n matrix composed of real entries, m<n,rankA=m.
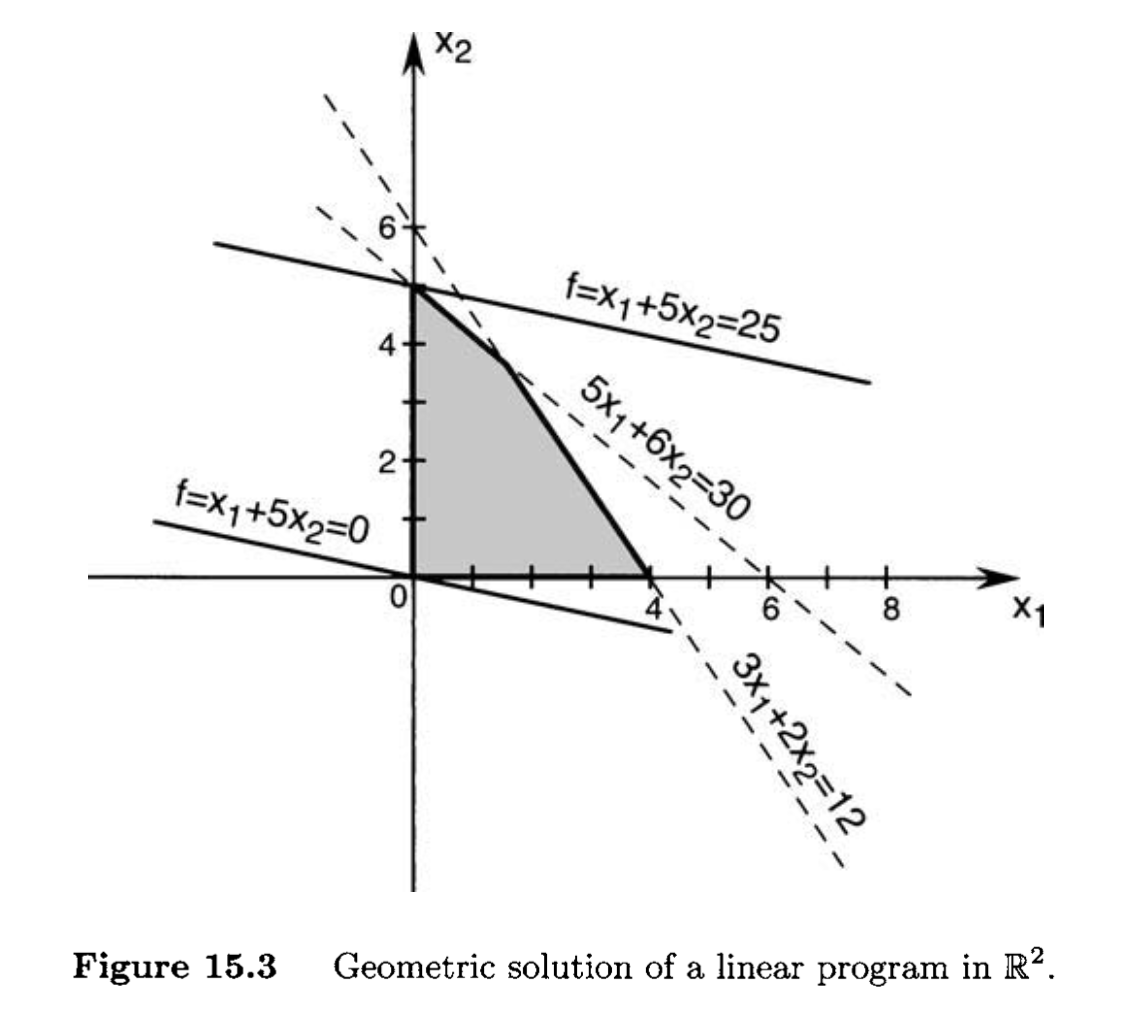
If a linear program is in the form
minimize subject to c⊤xAx≥bx≥0 then by introducing surplus variables yi, we can convert the original problem into the standard form
In more compact notation, the formulation above can be represented as minimizec⊤x
subject to Ax−Imy=[A,−Im][xy]=b
x≥0,y≥0, where Im is the m×m identity matrix.
If, on the other hand, the constraints have the form
Axx≤b≥0, then we introduce slack variables yi to convert the constraints into the form
Ax+Imy=[A,Im][xy]=bx≥0,y≥0 where y is the vector of slack variables. Note that neither surplus nor slack variables contribute to the objective function c⊤x.
In summary, to convert the problem into a standard form linear programming problem, we perform the following steps:
- Change the objective function to: minimize x1−x2.
- Substitute x1=−x1′.
- Write ∣x2∣≤2 as x2≤2 and −x2≤2.
- Introduce slack variables x3 and x4, and convert the inequalities above to x2+x3=2 and −x2+x4=2.
- Write x2=u−v,u,v≥0.
Basic Solutions
Definition
We call [xB⊤,0⊤]⊤ a basic solution to Ax=b with respect to the basis B. We refer to the components of the vector xB as basic variables and the columns of B as basic columns.
If some of the basic variables of a basic solution are zero, then the basic solution is said to be a degenerate basic solution.
A vector x satisfying Ax=b,x≥0, is said to be a feasible solution. A feasible solution that is also basic is called a basic feasible solution. If the basic feasible solution is a degenerate basic solution, then it is called a degenerate basic feasible solution.
Properties of Basic Solutions
Definition
Any vector x that yields the minimum value of the objective function c⊤x over the set of vectors satisfying the constraints Ax=b,x≥0, is said to be an optimal feasible solution.
An optimal feasible solution that is basic is said to be an optimal basic feasible solution.
Fundamental Theorem of LP
Consider a linear program in standard form.
- If there exists a feasible solution, then there exists a basic feasible solution.
- If there exists an optimal feasible solution, then there exists an optimal basic feasible solution.
Proof
We first prove part 1. Suppose that x=[x1,…,xn]⊤ is a feasible solution and it has p positive components. Without loss of generality, we can assume that the first p components are positive, whereas the remaining components are zero. Then, in terms of the columns of A=[a1,…,ap,…,an], this solution satisfies
x1a1+x2a2+⋯+xpap=b. There are now two cases to consider.
Case 1: If a1,a2,…,ap are linearly independent, then p≤m. If p=m, then the solution x is basic and the proof is done. If, on the other hand, p<m, then, since rankA=m, we can find m−p columns of A from the remaining n−p columns so that the resulting set of m columns forms a basis. Hence, the solution x is a (degenerate) basic feasible solution corresponding to the basis above.
Case 2: Assume that a1,a2,…,ap are linearly dependent. Then, there exist numbers yi,i=1,…,p, not all zero, such that
y1a1+y2a2+⋯+ypap=0. We can assume that there exists at least one yi that is positive, for if all the yi are nonpositive, we can multiply the equation above by −1. Multiply the equation by a scalar ε and subtract the resulting equation from x1a1+x2a2+ ⋯+xpap=b to obtain
(x1−εy1)a1+(x2−εy2)a2+⋯+(xp−εyp)ap=b. Let
y=[y1,…,yp,0,…,0]⊤ Then, for any ε we can write
A[x−εy]=b. Let ε=min{xi/yi:i=1,…,p,yi>0}. Then, the first p components of x−εy are nonnegative, and at least one of these components is zero. We then have a feasible solution with at most p−1 positive components. We can repeat this process until we get linearly independent columns of A, after which we are back to case 1 . Therefore, part 1 is proved.
We now prove part 2. Suppose that x=[x1,…,xn]⊤ is an optimal feasible solution and only the first p variables are nonzero. Then, we have two cases to consider. The first case is exactly the same as in part 1 . The second case follows the same arguments as in part 1 , but in addition we must show that x−εy is optimal for any ε. We do this by showing that c⊤y=0. To this end, assume that c⊤y=0. Note that for ε of sufficiently small magnitude (∣ε∣≤min{∣xi/yi∣:i=1,…,p,yi=0}), the vector x−εy is feasible. We can choose ε such that c⊤x>c⊤x−εc⊤y=c⊤(x−εy). This contradicts the optimality of x. We can now use the procedure from part 1 to obtain an optimal basic feasible solution from a given optimal feasible solution.